Identifying the Optimal Location for a New Business
MIDTERM PRESENTATION
November 13, 2017
W. Dai, A. Srivastava, R. Castellanes, D. First
Columbia University: Y. Garg, A. Mueller
Synergic Partners: G. Ribeiro
Agenda
- The Problem and Our Approach
- Literature Review
- Data Sources
- Initial Data Exploration
- Goals and Next Steps
THE PROBLEM AND OUR APPROACH
- Problem Statement
- Our Approach
The objective of this project is to identify the optimal location to open up a new business.
ASSUMPTIONS
- Begin with Chinese Restaurants and then expand
- Optimize towards maximizing profit
- Limited to Manhattan, New York
- We want the user to be able to decide for herself what factors to prioritize

PROBLEM STATEMENT
METHODOLOGY
Approach 1: Acquire a dataset of NYC Chinese restaurants and with their profitability, then understand drivers of profitability and model it
Problem: Dataset?
Approach 2: Focus on business considerations that are drivers of profitability: revenue, cost, competition, and closeness to transportation
Example
We do not know the costs of real estate for restaurants, so we will use publicly available real estate prices instead
Recommending a location based on user preference
- The user will rank how much they care about each of these factors
-
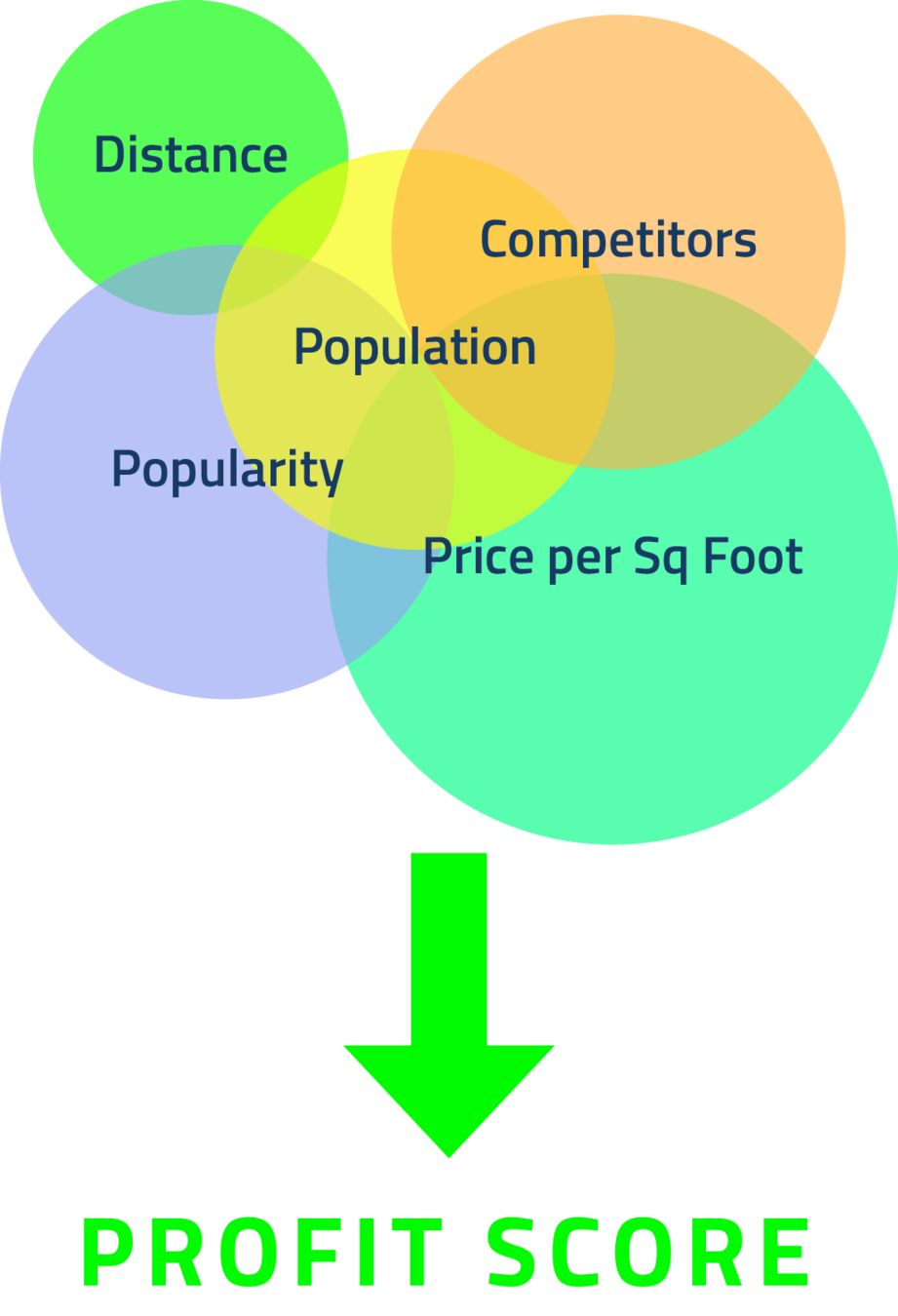
For each NYC location area, we derive a score to each restaurant for four categories:
- Expected popularity
- Cost
- Competition
- Distance to subways
- A location is then selected that scores highest on these factors
1
2
3
Profit Score
Recommending a location based on user preference
- The user will rank how much they care about each of these factors
-
For each restaurant, we derive assign a static score to each restaurant for four categories:
- Profit and Popularity
- Cost
- Competition
- Distance to subways
- A location is then selected that scores highest on these factors
Example:
1
2
3
Profit Score
1
2
3
"I want a low-cost restaurant in a popular area, somewhat close to subways. I don't care about competition, because I'll differentiate."
1
.5
0
.5
Coefficients
Location 1
Location 2
Location 3
Location 4
1
0
.5
.75
.25
.30
.60
.15
.80
.20
.20
.15
.40
.60
.80
.90
Total Score
1.325
.45
1.2
.506
Recommend Location 1
Cost
Popularity
Comp.
Transportation
Literature Review
Unsupervised Learning: Collaborative Filtering
In Eravci et al., the authors divided up NYC into neighborhoods. Then they used collaborative filtering to recommend businesses to new neighborhoods
Recommendations based on Linear combination of Drivers of Profitability
Two approaches have been taken in the literature
In Khateryna et al., the authors generate a location recommendation for Ukranian businesses based on combining the estimated profits and costs for different locations.
Our Approach
Problem: We want to give more granular-level recommendations
We want to allow the user to prioritize cost vs. popularity, and the like
We will integrate various
publicly-available datasets
In the CF approach, which is not in our model, the authors split up NYC into neighborhoods based on an unsupervised clustering method
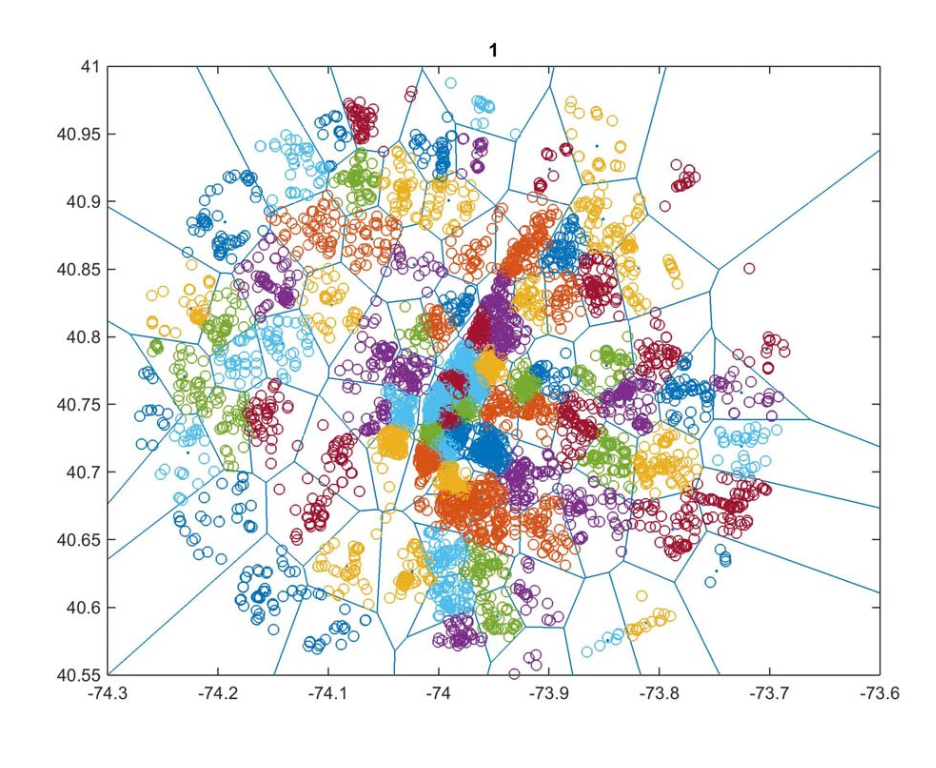
EXAMPLE: CLUSTERING
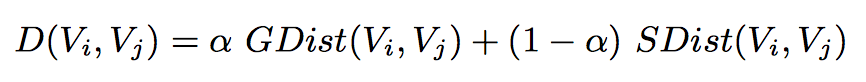
DISTANCE
http://ieeexplore.ieee.org/stamp/stamp.jsp?arnumber=7836791
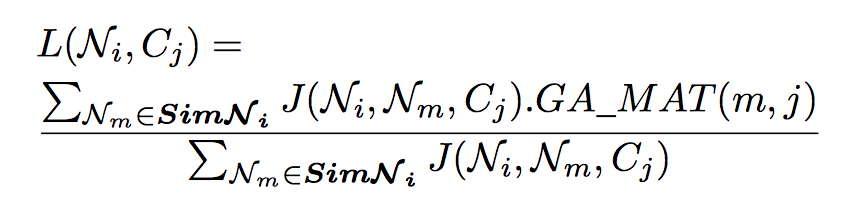
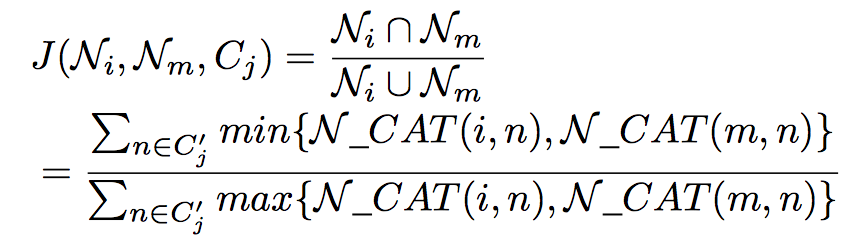
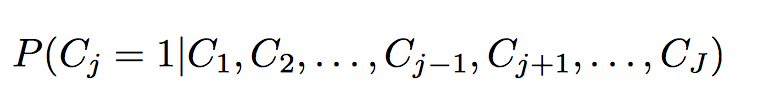
PROBABLISTIC NEIGHBORHOOD SELECTION
COLLABORATIVE FILTERING
DATA SOURCES
- Yelp
- Foursquare
- NYC Open Data
- Loopnet
Example:
1
2
3
"I want a low-cost restaurant in a popular area, somewhat close to subways. I don't care about competition, because I'll differentiate."
1
.5
0
.5
Coefficients
Location 1
Location 2
Location 3
Location 4
1
0
.5
.75
.25
.30
.60
.15
.80
.20
.20
.15
.40
.60
.80
.90
Total Score
1.325
.45
1.2
.506
Recommend Location 1
Cost
Popularity
Comp.
Transportation
We integrated various data sources in order to score each location on four metrics
Expected Popularity
Distance to Subways
Cost of Real Estate
Competition
Dataset
LoopNet
Yelp
Foursquare
Demographic Data (NYC Open Data)
Yelp
Foursquare
NYC Open Data
Metric
Yelp
Dataset: ~1,000 Chinese Restaurants in NYC
Fields Collected:
- Name
- Latitude
- Longitude
- Price
- Rating
- Number of Reviews
Foursquare
Dataset: ~600 Chinese Restaurants in NYC
Fields Collected:
- Name
- Latitude
- Longitude
- Check-ins
- Visitors
NYC OPEN DATA
Datasets Collected:
- Population by Zip Code (cut by Age and Sex)
- Subway Latitude and Longitude
- Bus Stop Latitude and Longitude
LOOPNET
Background: Loopnet lists out commercial real estate listings, including retail spaces
Parameters: We limited our search to NYC listings of locations <2000 SF, ground level
- Vacant Address
- Price per Sq. Ft. per Rent
- Derived latitude and longitude
INITIAL DATA EXPLORATION
- Price per Square Feet
- Density of Chinese Restaurants
- Number of Reviews
- Ratings
- Initial Profit Score
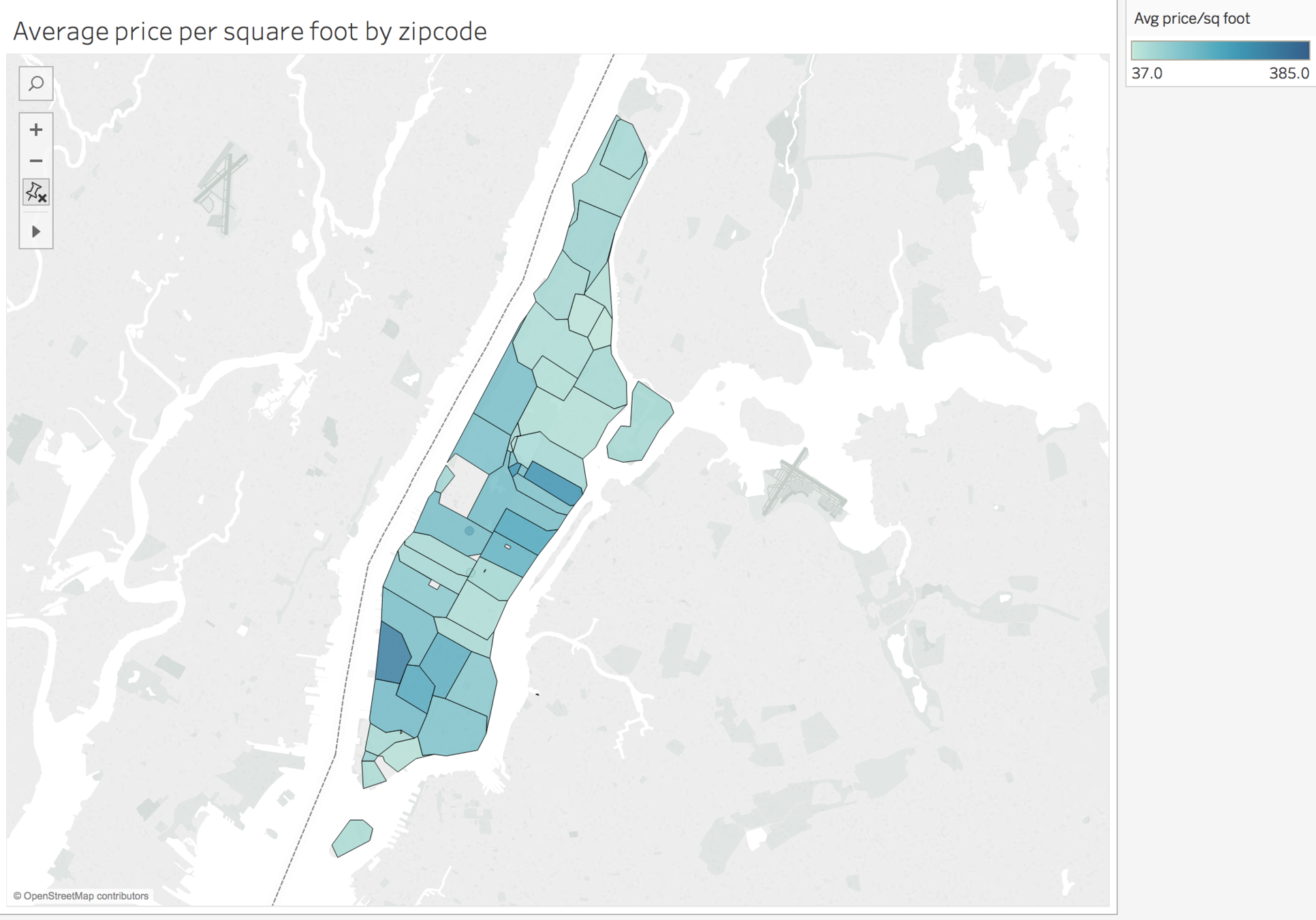
PRICEST ARE HIGHEST IN marquee RETAIL NEIGHBORHOODS
Tribeca and Midtown Manhattan, expensive retail neighborhoods, show the highest price per square foot per year
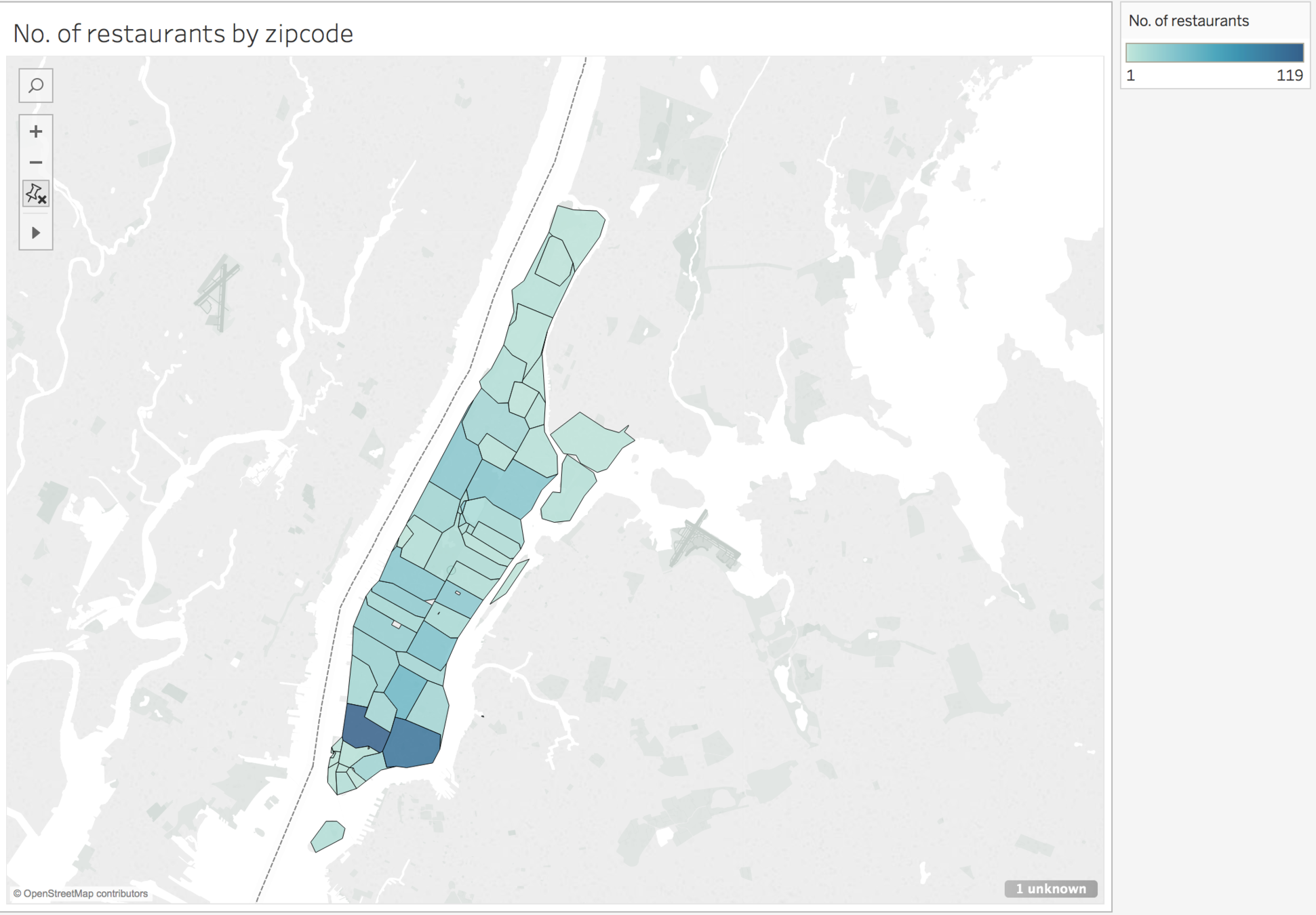
As expected, chinatown has the highest density of chinese restaurants
Other neighborhoods have a significantly lower and consistent density of Chinese Restaurants
Downtown Manhattan's Chinese restuarants seem to be the most popular
Both no. of reviews (Yelp) and checkins (Foursquare) seem to be highest for lower Manhattan
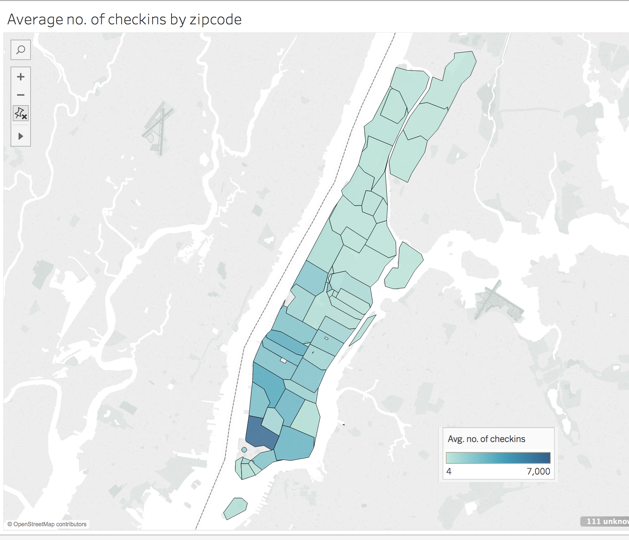

RATINGS ARE INCONSISTENT ACROSS NEIGHBORHOODS
In general, downtown generated higher ratings than uptown
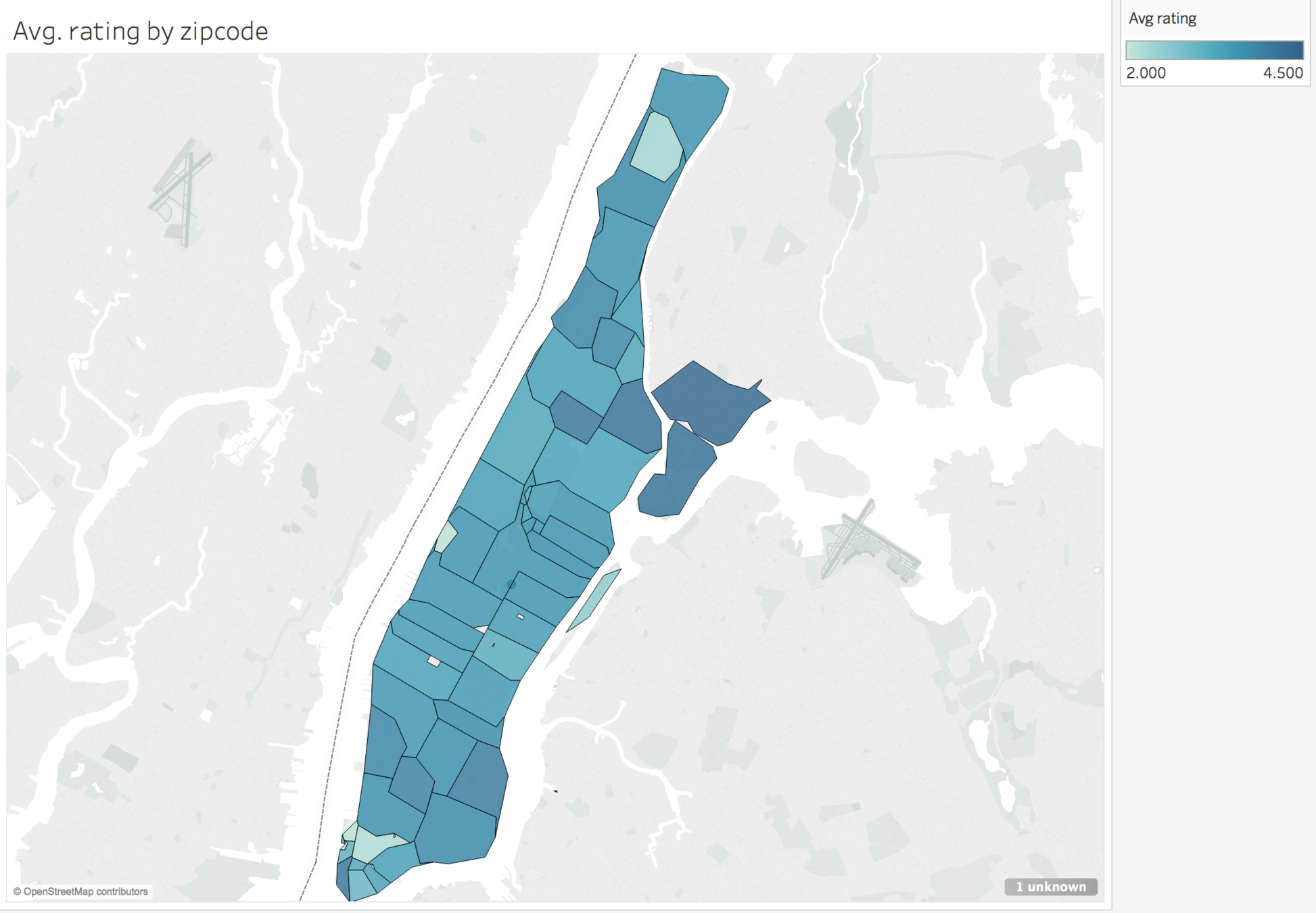
OUR INITIAL PROFIT SCORE PROJECTS HIGHEST PROFIT ON THE UPPER WEST SIDE
Areas with high density of Chinese Restaurants and fewer reviews show lower profit scores at this point
For our initial model, we weighed each factor equally: expected popularity, expected cost, competition, and distance to subways: Coef = [1,1,1,1,]
GOALS AND NEXT STEPS
- Define Location Areas
- Model Target Scores
- Create Web App
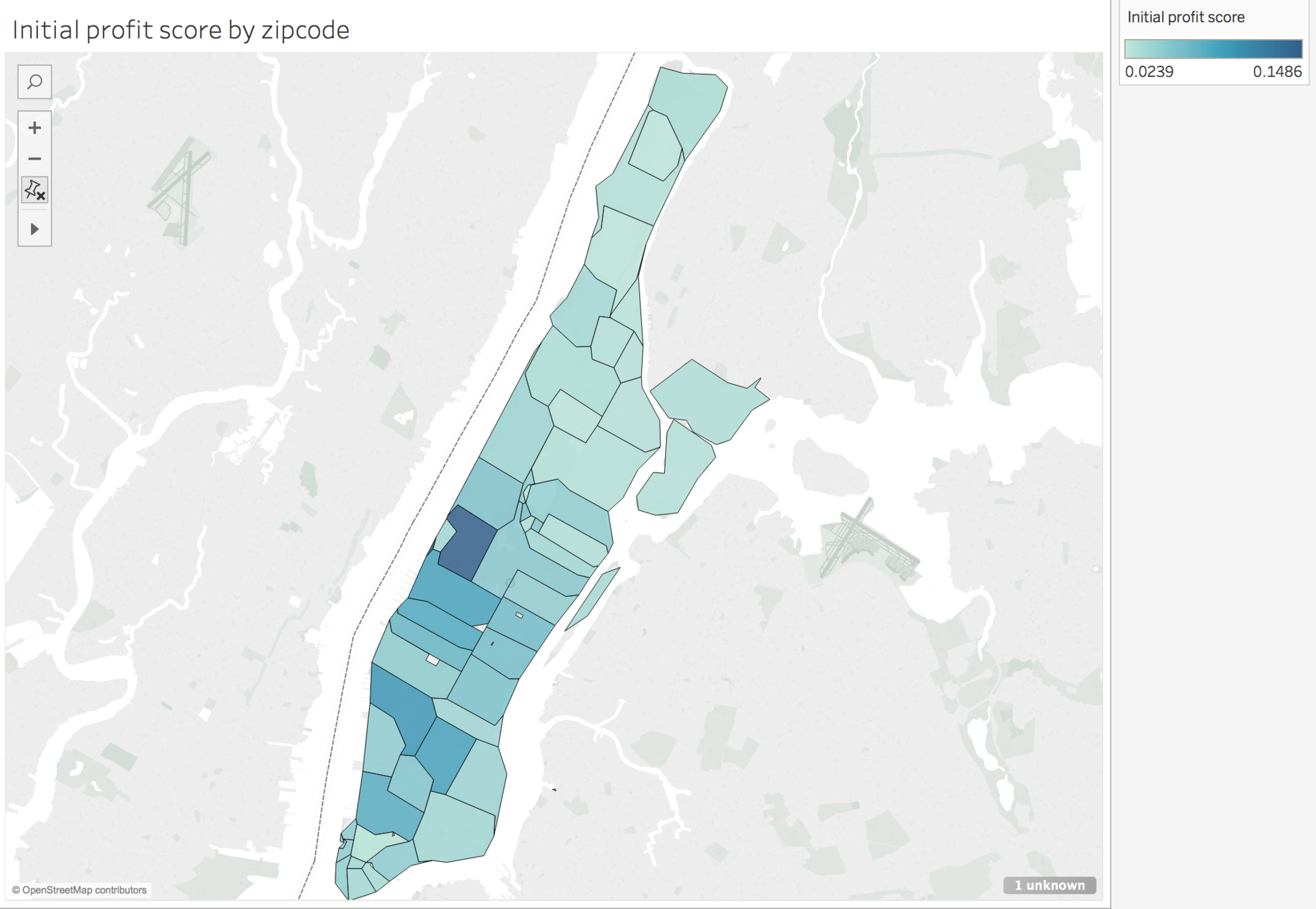
DEFINE LOCATION AREAS
In this, we will cluster locations based on price per square foot per year and distance
Once we see clusters that make sense, we will create their respective shape files that will serve as location areas.
FINE TUNE TARGET SCORE
We will fine-tune a meaningful target score that well-represents estimated profit at the locations we have defined.
Example:
1
2
3
"I want a low-cost restaurant in a popular area, somewhat close to subways. I don't care about competition, because I'll differentiate."
?
?
?
?
Coefficients
Location 1
Location 2
Location 3
Location 4
1
0
.5
.75
.25
.30
.60
.15
.80
.20
.20
.15
.40
.60
.80
.90
Total Score
?
?
?
?
Recommend ?
Cost
Popularity
Comp.
Transportation
Final output - WEB APP OF RECOMMENDED LOCATION AREAS BASED ON USER INPUT
- INPUT PAGE 1
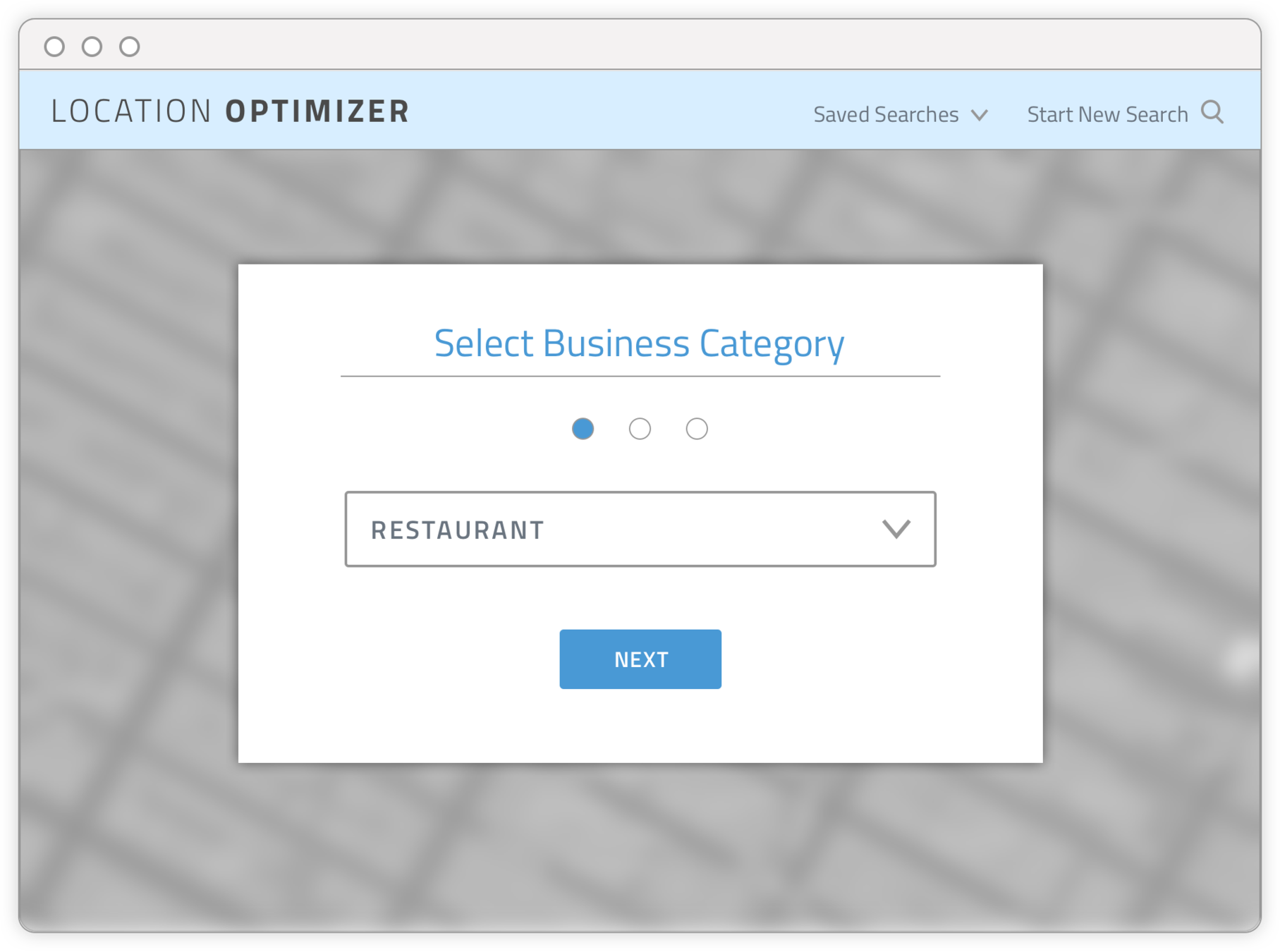
Final output - WEB APP OF RECOMMENDED LOCATION AREAS BASED ON USER INPUT
- INPUT PAGE 2
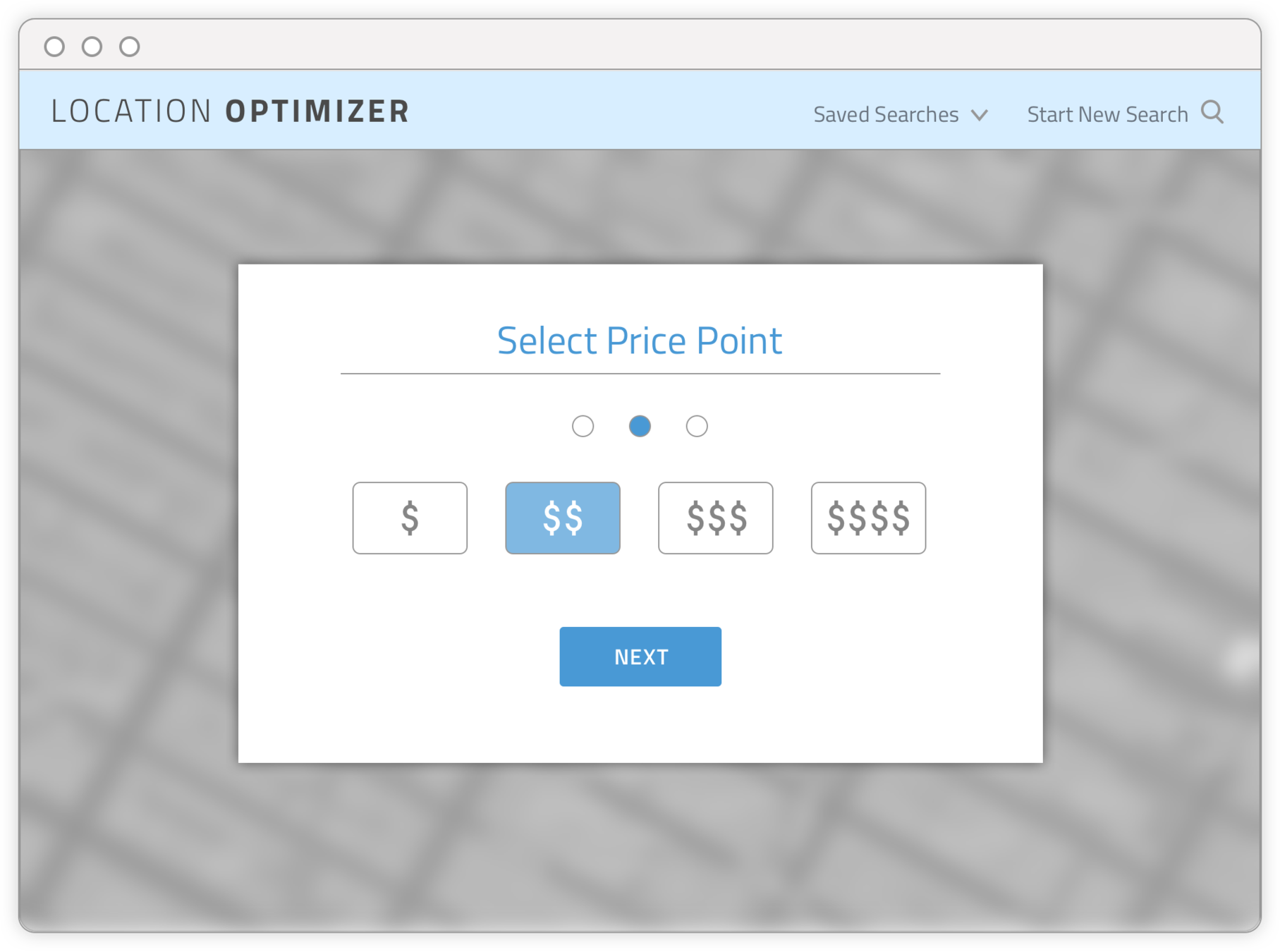
Final output - WEB APP OF RECOMMENDED LOCATION AREAS BASED ON USER INPUT - RESULTS PAGE
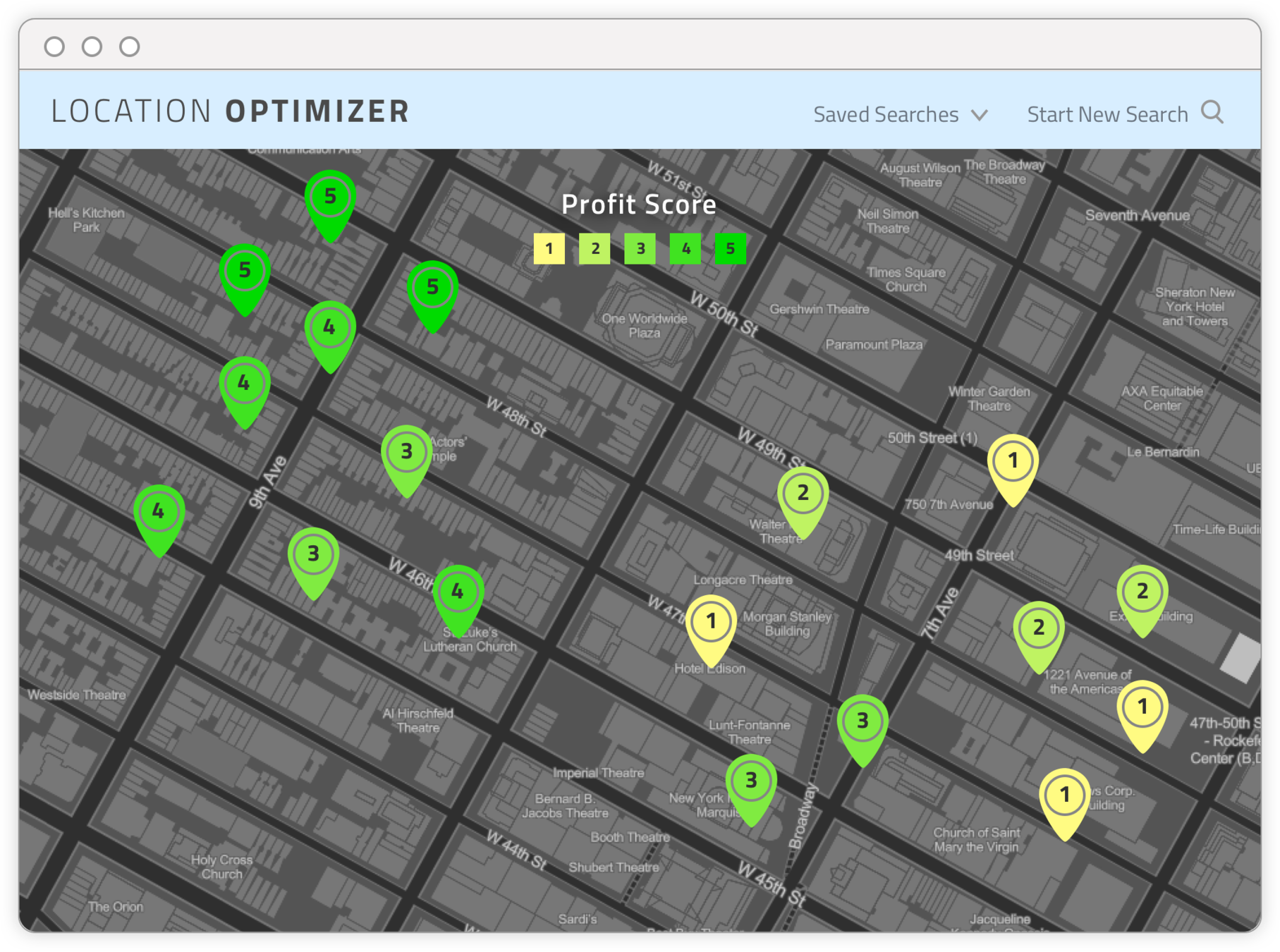
APPENDIX
Estimating Revenue
Revenue
# of Customers
$$ per Order
=
x
- Our target variable
- Can be assumed constant
(e.g. Chinese Restaurants can expect $20 per order)
- We will need to estimate this with data we have collected
Estimating COSTS
Total Cost
Fixed Costs
Variable Costs
=
+
- Our target variable
- The main variable cost is retail space rental, which varies by location
- A lot can be assumed to be fixed. For Chinese Restaurants:
- Overhead
- Maintenance
- Size of Restaurant
- Staff
MODELING APPROACH
We will look into a sample of following features that could potentially impact overall profit:
- Distance from nearby subways and bus stops
-
Populations by zip code by age and gender
- Population density
- Number of competitor businesses in the vicinity
-
Estimates of popularity
- Yelp rating
- Foursquare checkins
- ... And of course, price per square foot per year
Zillow
Dataset: All neighborhoods and zip codes in NYC
Fields Collected:
- Neighborhood
- Zip Score
- Zestimate rank (gives an idea of home price)